Vom 12. bis 15. Juli waren unsere Dienste offline. Auslöser war ein Fehler unseres Ceph-Storage-Clusters, nach dem wir alle Datenbanken wiederherstellen mussten.
Hinweis: Die Erklärungen und Grafiken in diesem Post sind teilweise vereinfacht und dienen vor allem der Verstehbarkeit der Zusammenhänge, nicht der vollständigen Erklärung der beschriebenen Systeme.
Kurzer Überblick über unsere Infrastruktur
Teckids betreibt, mit Hilfe eines großzügigen und langjährigen Sponsorings der Firma Speedparner, souveräne Infrastruktur in einem Rechenzentrum in Düsseldorf. Kern davon ist ein Cluster aus vier Proxmox-VE- Servern, die sowohl den Betrieb der virtuellen Maschinen als auch Netzwerk-Storage auf Basis von Ceph übernehmen.
Die meiste Hardware ist gebraucht oder sehr alt, mit Ausnahme von zwei Servern, die wir 2018 und 2019 beim Thomas-Krenn-Award gewonnen hatten. Diese sind jedoch nicht sehr leistungsfähig.
Das größte Problem im Betrieb unserer Dienste in den letzten Jahren
war die mangelhafte Performance des Storage. Zur Einordnung: Ein einfacher
apt install des vim-Editors auf einer VM konnte bis zu 5 Minuten
dauern. Ursache dafür waren vor allem langsame, mechanische Festplatten.
Ausbau und Optimierung des Storage
Mit dem Finanzabschluss unseres Vereinsjahres 2022/2023 haben wir beschlossen, in die teilweise Modernisierung unserer technischen Infrastruktur zu investieren und dabei mit dem Austausch alle mechanischen Festplatten durch SSDs zu beginnen. Für etwas über 2000 € haben wir deshalb Anfang Juli 14 NAS-taugliche SSDs gekauft.
In einem Ceph-Cluster sind die Daten (Objekte) in so genannte Placement Groups organisiert, die wiederum auf OSDs verteitl sind. Die OSDs bilden eine Hierarchie, die die physische Verteilung der Datenträger wiederspiegelt. Mittels der CRUSH-Map garantiert Ceph dann eine bestimmte Verteilung, z.B. um Verfügbarkeit und redundante Kopien sicherzustellen. Wenn sich diese Topologie ändert, bspw. durch Ausfall eines Datenträgers oder das gezielte Hinzufügen oder Entfernen, werden Daten neu verteilt, so dass die gewünschten Garantien wiederhergestellt werden.
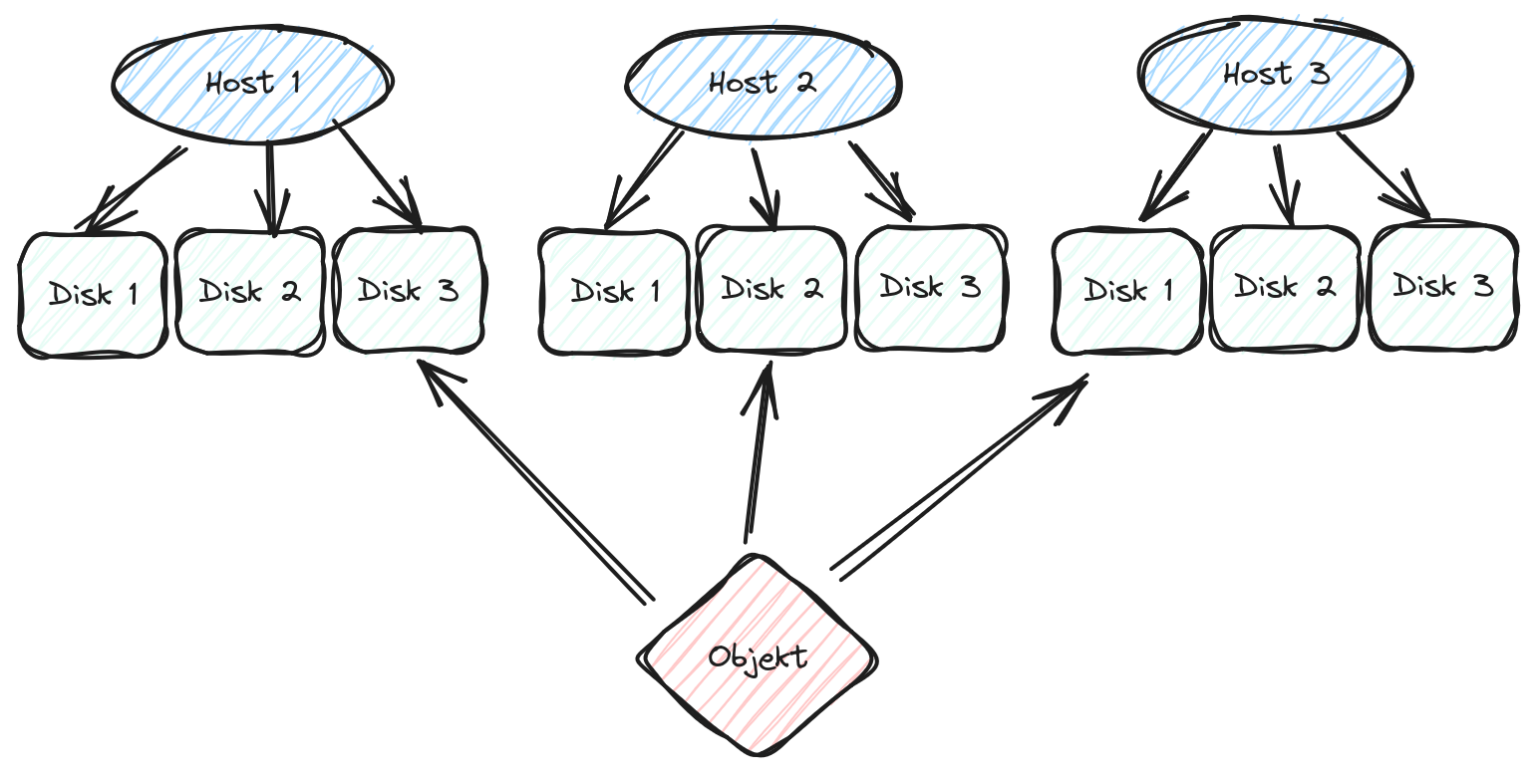
Für den Umbau unseres Storage mussten also verschiedene Überlegungen angestellt werden:
- Wieviele und welche Datenträger können gleichzeitig ersetzt werden, so dass zu keiner Zeit zu wenig Speicherplatz vorhanden ist?
- Wie reduzieren wir die Auswirkungen der Umverteilung (Rebalancing) während des Umbaus?
- Wie werden die Datenträgern in den Servern veteilt, so dass einigermaßen gleichmäßig Speicherplatz zur Verfügung steht?
Ausfall des Storage
Da auch der Platz für Datenträger in den Servern begrenzt ist, entschieden wir uns, zunächst den bisher vorhandenen, kleinen SSD-Cache zu deaktivieren. Das würde zwar vorübergehend zu noch schlechterer Performance führen, aber dafür die Dauer der Umbaumaßnahmen immens reduzieren. Deshalb haben wir als ersten Schritt am Freitag, dem 12. Juli, den Cache vom writeback- in den readproxy-Modus umgeschaltet. In diesem Modus sollten noch im Cache vorhandene Objekte benutzt, jedoch keine neuen Objekte mehr gecachet, werden.
In diesem Moment meldeten die ersten VMs Dateisystemfehler und es kam zu Crashes der ersten Prozesse. Die tatsächliche Ursache hierfür konnten wir leider nicht gesichert feststellen. Am wahrscheinlichsten ist, dass eine schon länger vorhandene Inkonsistenz einiger Objekte im Ceph-Storage durch den Cache bisher verdeckt wurde. In dem Moment, in dem der Cache de facto deaktiviert wurde, wurden daher inkonsistente Daten ausgeliefert.
Erster Wiederanlauf der Dienste und PostgreSQL-Crash
Der erste Wiederanlauf der Dienste wurde direkt nach dem Crash versucht. Die betroffenen
Dateisysteme wurden mittels fsck geprüft und repariert und die VMs dann wieder
regulär hochgefahren. In der Folge kam es jedoch erneut zu Fehlern; insbesondere
der PostgreSQL-Cluster ließ sich nicht starten.
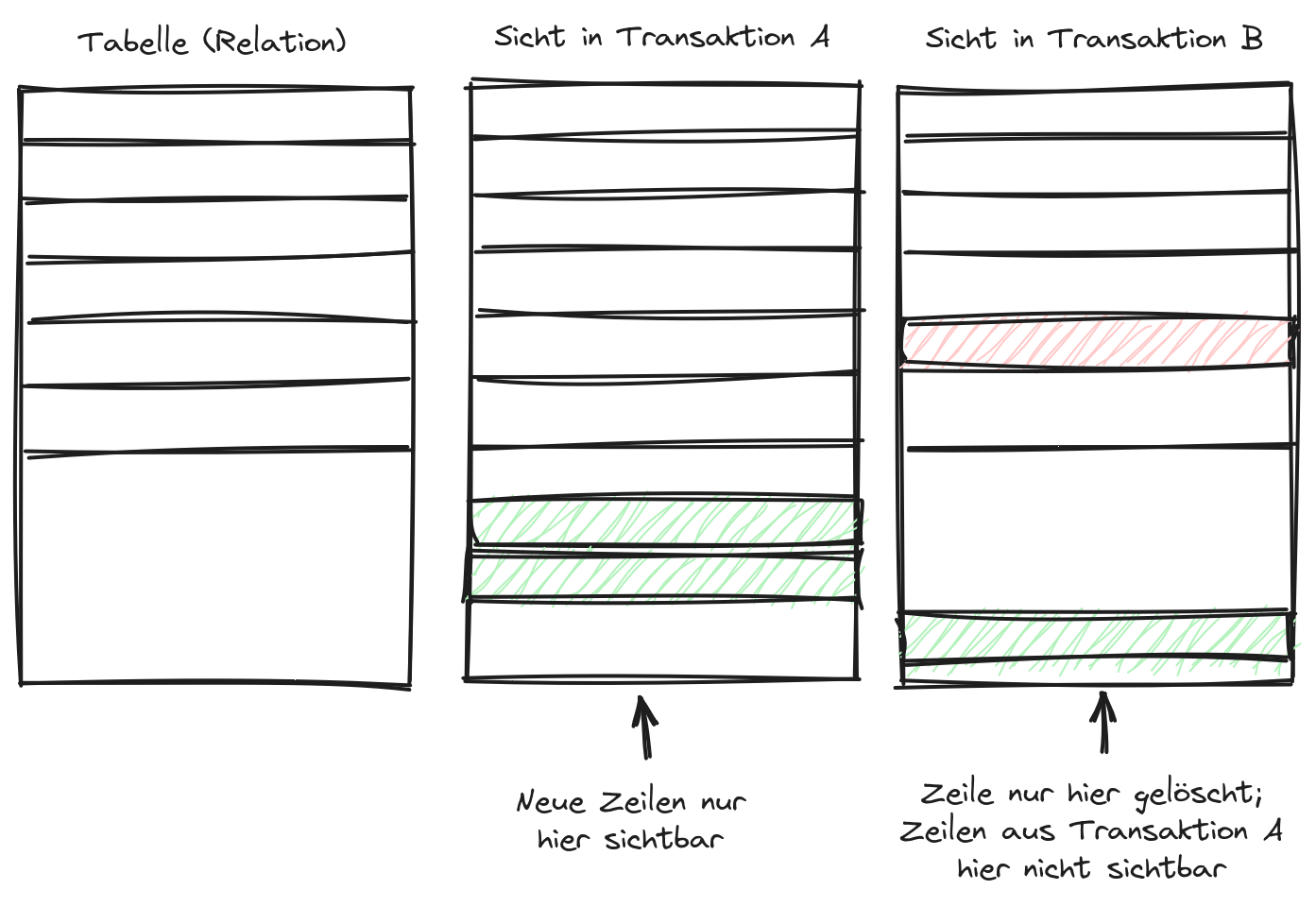
Eines der Grundprinzipien in Datenbank-Management-Systemen sind nebenläufige Transaktionen. Jeder Zugriff auf die Daten einer Datenbank wird in eine so genannte Transaktion gekapselt. Das Datenbank-Management-System stellt sicher, dass das genaue Bild über die Daten innerhalb einer Transaktion konsistent ist. Wenn mehrere Clients gleichzeitig zugreifen und Daten verändern, dann darf das keinen direkten Einfluss auf andere Clients haben. Dieses und andere Prinzipien kann man unter der Abkürzung ACID zusammenfassen.
Nach der Korrektur der Dateisystemfehler auf dem System, auf dem unser PostgreSQL-Cluster läuft, fehlten Informationen über bereits vergebene Transaktions-Nummern und weitere verwandte Informationen. Notwendigerweise entschieden wir uns deshalb, den PostgreSQL-Cluster vollständig aus einem Backup wiederherzustellen.
Restore der PostgreSQL-Datenbanken auf unserem langsamsten Server
Drei gute Nachrichten vorab: Wir hatten ein Backup des PostgreSQL-Clusters, es war aktuell und es ließ sich wiederherstellen! Was wir zu diesem Zeitpunkt noch nicht wussten, war, dass uns eine dieser drei "guten" Nachrichten zum Verhängnis werden würde.
Zunächst mussten wir uns für eine Kompromisslösung entscheiden, wie wir die immerhin etwa 350 GiB Daten einigermaßen schnell wiederherstellen wollten. Dabei gab es einige Eckpunkte zu beachten:
- Das letzte volle Backup des Clusters war fünf Tage alt. Alle Daten zwischen dem 7. und dem 12. Juli mussten aus dem Write Ahead Log wiederhergestellt werden.
- Der Storage auf dem Datenbankserver war nach der Deaktivierung des Caches nun noch langsamer als vorher
- Der Backup-Server hat mittelmäßige Storage-Geschwindigkeiten, aber nur eine Single-Core-CPU mit 2,1 GHz
- Es stand, unabhängig von dem Restore, ein Upgrade von PostgreSQL 13 auf 16 an
Letztendlich haben wir uns entschieden, folgendermaßen vorzugehen:
- Restore des Backups auf dem Backup-Server
- Initialisierung eines neuen PostgreSQL-16-Clusters auf dem Datenbank-Server
- Übertragung der Daten als SQL-Dump in den neuen Cluster
Das Restore des Datenbank-Clusters aus dem Write Ahead Log dauerte etwa 1½ Tage. Danach startete PostgreSQL erfolgreich und der Zugriff auf alle Datenbanken war mit aktuellem Stand möglich.
Inkonsistenzen im Backup und Reparatur
Nachdem der Zugriff auf den Backup-Cluster hergestellt war, konnten wir mit dem Übertragen des SQL-Dumps beginnen. Das funktionierte zunächst erwartungsgemäß gut, mit einer erwarteten Dauer von etwa einem halben Tag.
Leider brach der Prozess beim Übertragen der Datenbank von Synapse ab, da auch hier korrupte Transaktions-Informationen vorlagen. Überraschenderweise zeigte sich im Backup ein ähnliches Fehlerbild wie auf dem Produktivsystem.
An dieser Stelle wäre der sichere Weg gewesen, das Restore des Datenbank-Clusters zu wiederholen und dabei ein Point-in-Time-Recovery zu einem Punkt kurz vor dem Auftreten der ersten Dateisystemfehler zu machen. Das hätte die verfügbare Zeit für die Wiederherstellung jedoch massiv überschritten, da am Dienstag ein wichtiger Entwicklungs-Sprint des AlekSIS-Projekts beginnen sollte.
Deshalb haben wir uns stattdessen entschlossen, die betroffenen Tabellen zu identifizieren und zu beurteilen, ob die Fehler vernachlässigbar sind. Tatsächlich waren dann auch nur zwei Tabellen betroffen – bei beiden handelte es sich um reine Caching-Tabellen, die Public Keys anderer Matrix-Server cachen. Diese Tabellen ließen wir dann leer, mit dem Wissen, dass Nachrichten von Matrix-Servern, die mittlerweile offline sind, dann nicht mehr verifiziert werden können. Diesen minimalen Verlust wollten wir in Kauf nehmen.
Nachdem alle anderen Datenbanken und Tabellen wiederhergestellt waren, stellte sich jedoch heraus, dass es weitere Inkonsistenzen gab. Einigen Tabellen fehlten Primary Keys. Ursache war, dass das Anlegen der entsprechenden Constraints beim Einspielen des SQL-Dumps fehlgeschlagen war.
Tabellen in relationalen Datenbanken können so genannte Constraints besitzen, die
verschiedene Prüfungen über die Daten in der Tabelle erzwingen. Der wohl bekannteste
Constraint ist der UNIQUE-Constraint, der verhindert, dass Daten doppelt eingefügt
werden. Ein Spezialfall davon wiederum ist der Primary Key, der sicherstellt, dass
eine Tabellenzeile eindeutig benannt werden kann.
Beim Versuch, die fehlenden Primary Keys selber anzulegen, zeigte sich, dass die betroffenen Tabellen tatsächlich einige Daten doppelt enthielten. Betroffen waren dabei die Datenbanken von Syanpse und Mastodon. Glücklicherweise stellten wir fest, dass alle betroffenen Tabellen in zwei Kategorien fielen:
- Tabellen, deren Daten durch Föderation erneut befüllt werden können
- Tabellen, deren Primary Key oder
UNIQUE-Cosntraint eine global eindeutige ID enthielt (z.B. die Matrix-Room-ID oder eine (Short)-UUID)
Im zweiten Fall war daher klar, dass die doppelten Datensätze bei einem INSERT OR UPDATE
oder einer vergleichbaren Operation entstanden sein mussten, weshalb der neuere Datensatz
vorzuziehen war. In den Fällen, in denen kein Zeitstempel oder ähnliches vorhanden war,
haben wir stattdessen die interne Tupel-ID von PostgreSQL (ctid) verwendet:
-- Zwei beispielhafte Lösch-Operationen
DELETE FROM
receipts_linearized a USING receipts_linearized b
WHERE a.ctid < b.ctid
AND a.room_id = b.room_id
AND a.receipt_type = b.receipt_type
AND a.user_id=b.user_id;
DELETE FROM sessions a USING sessions b WHERE a.ctid < b.ctid AND a.id = b.id;
Nachdem wir die Integrität der Tabellen so wiederhergestellt hatten, konnten wir durch ein
erneutes Einspielen eines SQL-Dumps mit der pg_dump-Option --schema-only die zuvor
fehlenden Contraints, Indexe und Keys anlegen und die Dienste problemlos starten.
Performance-Probleme nach dem Wiederanlauf
Leider stellte sich insbesondere der Matrix-Server in der Folge als weitestgehend
unbenutzbar heraus. Ein Blick auf den Datenbankserver zeigte, dass fast alle Backend-
Prozesse für Synapse im D-Status waren, d.h. wahrscheinlich auf Datenträger warteten.
Bei fast allen handelte es sich um SELECT-Statements, also um lesende Zugriffe auf die
Datenbank. Da das System mit ausreichend Arbeitspeicher versehen ist und eigentlich
weitestgehend aus den shared_buffers von PostgreSQL und aus dem VFS-Cache des
Betriebssystems arbeiten sollte, war das überraschend. Es stellte sich dann heraus.
Was die meisten als Chat-Plattform kennen, ist eigentlich eine große, veteilte Graph-Datenbank. Matrix-Räume sind eine Abfolge von Events, die jeder beteiligte Server in den Graphen des Raumes einfügen kann. Wenn verschiedene Server oder sogar Clients am selben Server sozusagen "zeitgleich" ein neues Event an derselben Stelle einfügen, ist der Graph, also die Abfolge der Events und Nachrichten, nicht mehr linear. Weil aber die meisten Clients, eben alle Chat-Anwendungen, eine einfache chronologische Abfolge der Nachrichten erwarten, muss der Graph linearisiert werden.
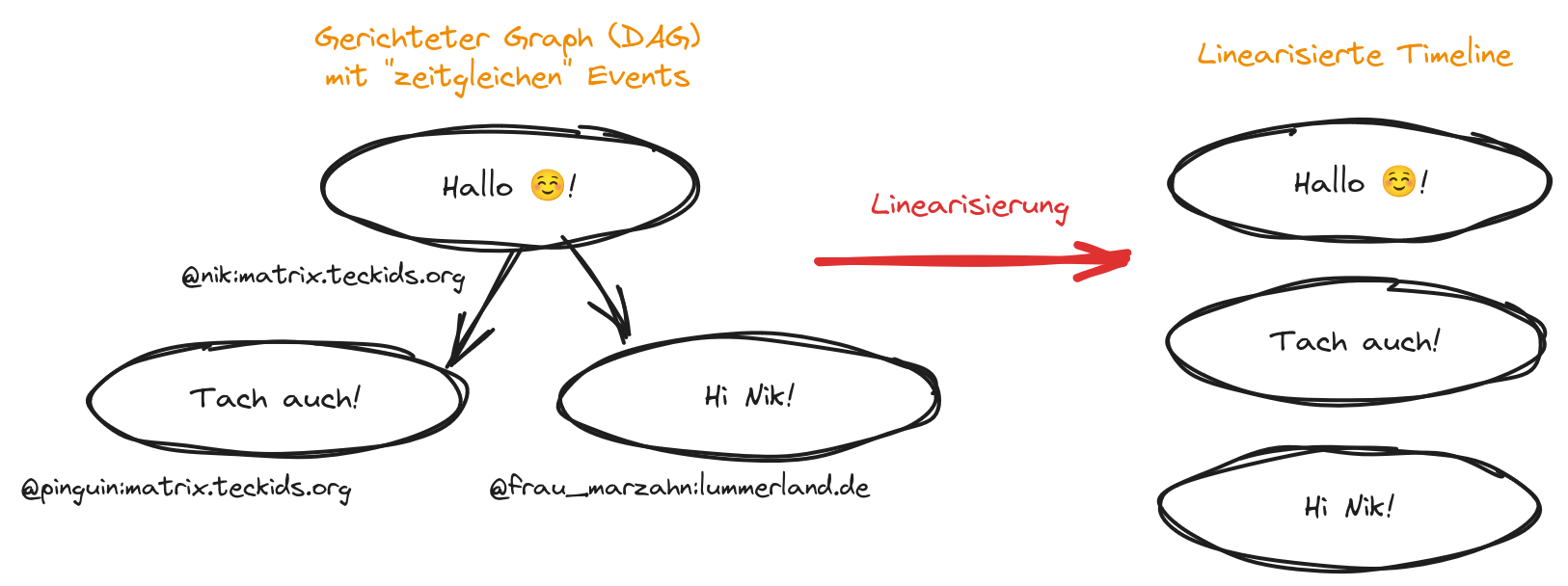
Diese komplexe Operation erledigt Synapse direkt in der Datenbank. Durch die lange Ausfallzeit und die Tatsache, dass einige unserer Benutzer*innen in vielen, teils sehr großen und aktiven, Matrix-Räumen sind, wurden diese Operationen sehr umfangreich und mussten mit großen Datenmengen arbeiten.
PostgreSQL stellt jeder Operation einer Abfrage eine vorgegebene Menge an Arbeitsspeicher zur Verfügung. Benötigt eine Operation, bspw. ein Sortier- oder ein Hashing-Algorithmus, mehr als diesen Speicher, muss er Daten in temporäre Dateien auslagern.
Das passierte in unserem Fall nun ständig, was dem ohnehin langsamen Storage nicht zuträglich
war. Nach entsprechender Auswertung stellten wir fest, dass Synapse für seine Auswertungen
aktuell etwa 512 MiB Arbeitsspeicher benötigte. Dieser Wert wäre für alle anderen Anwendungen
extrem hoch und könnte schnell zu Speicherproblemen führen. Praktischerweise kann PostgreSQL
dieses Limit auch pro Datenbank setzen, so dass wir Clients der Synapse-Datenbank ein höheres
work_mem-Limit zuweisen konnten:
ALTER DATABASE synapse SET work_mem TO '512 MB';
Danach war der Matrix-Server problemlos nutzbar under Rückstand schnell abgearbeitet.
Verlust des Kerberos-Master-Keys
Schon vor langer Zeit haben wir unsere Systeme und Plattformen auf das Single-Sign-On- System OpenID Connect umgestellt. Zwei Systeme benutzten jedoch weiterhin LDAP und Kerberos:
- Unser Ticket-Sytem Zammad
- Der XMPP-Server ejabberd
Außerdem hatte unsere aktuelle SSO-Plattform TIC-Desk noch ein Fallback auf das alte System fur Benutzer*innen, die ihr Passwort noch nicht im neuen System gesetzt hatten.
Da diese Übergangslösung eigentlich abgeschafft werden sollte, hatten wir LDAP und Kerberos beim Backup schon länger nicht mehr berücksichtigt. Leider bedeutet das, dass wir durch die Dateisystemprobleme den Master Key, der die Daten in der Kerberos-Datenbank verschlüsselt, verloren haben. Damit war kein Login mehr in Jabber und Zammad möglich.
Nach einigen Überlegungen haben wir uns entschlossen, das alte System aus diesem Anlass nun endgültig abzuschaffen und mit den daraus folgenden Konsequenzen zu leben:
- Zammad benötigt vorübergehend lokale Passwörter, bis die Entwickler OIDC einführen
- Der XMPP-Server ist vorübergehend offline und wird bei Gelegenheit zu Prosody migriert
- Die Benutzer*innen, die in TIC-Desk noch kein Passwort gesetzt hatten, benötigen einen manuellen Passwort-Reset durch uns
Ursachenanalyse und Lessons learnt
Ursächlich war letztendlich, dass das Entfernen eines Caching-Tiers aus Ceph nicht online möglich ist, wenn man Ceph für Block-Devices (RBD) benutzt. Das ist nicht komplett unbekannt, aber auch nicht offensichtlich dokumentiert. Beim Entfernen des Caches wurden kurzzeitig im Zugriff befindliche Blöcke der Dateisysteme mit ungültigen oder veralteten Daten ausgeliefert.
Bei dem Backup-Mechanismus, den wir für PostgreSQL verwenden (Streaming-Backup zu Barman) wird das Write Ahead Log direkt an den Backup-Server übertragen. Dies erfolgt aus den WAL-Buffern im Arbeitsspeicher oder aber aus den WAL-Dateien auf dem Datenträger, falls die Übertragung länger dauert. Durch die insgesamt hohe Schreiblast auf unseren Datenbanken wurden WAL-Daten vom Datenträger ins Backup übertragen, wodurch auch korrupte Daten übetragen wurden.
Die duplizierten Daten resultierten daraus, dass durch korrupte Transaktions-Daten nun eigentlich gelöschte Daten wieder sichtbar wurden (anhand des obigen, vereinfachten Bildes kann man sich gut vorstellen, wie eine Tabelle aussieht, wenn die beiden Transaktionen A und B übereinandergelegt werden statt in eine kohärente Reihenfolge gebracht zu werden).
Durch den Ausfall und die Behebung haben wir viele Dinge gelernt, nicht zuletzt auch über die Struktur und Interna der von uns betriebenen Anwendungen.
Insbesondere seien aber folgende Punkte hervorzuheben:
- Das Cache-Tiering in Ceph ist instabil. Da es auch nur in seltenen Fällen wirklich Performance-Vorteile bringt, sollte es vermieden werden. Eine gute Alternative, um Storage aus mechanischen Festplatten zu beschleunigen, ist es, das WAL der Bluestore- Datenbank auf SSDs auszulagern.
- Im Falle auftretender Dateisystem-Korruptionen sollten die Grundsätze der IT-Forensik angewendet werden und sofort in einen Read-Only-Modus gewechselt werden. Auch Backup- Prozesse sollten sofort angehalten werden.
- ext4 ist kein robustes Dateisystem, was Datenintegrität angeht. Auch
fsckfindet eklatante Probleme nicht und kann ein de facto vollständig unbrauchbares Dateisystem als sauber betrachten. Mittlerweile sollten moderne Dateisyteme wie btrfs, deren Architektur bereits Datenintegrität im Kern enthält, eine ernsthafte Alternative sein - Beim Recovery von PostgreSQL aus WAL-Archiven sollte direkt beachtet werden, korrupte Segmente, die nach einem Katastrophenfall angefallen sind, nicht mit zu recovern
- Es sollte einen dokumentierten Mechanismus geben, um Kernkomponenten wie das SSO unabhängig von anderen Diensten zu starten
Zum Vorgehen unserer Datenbank-Restoration möchten wir außerdem anmerken, dass die von uns ausgeführten manuellen Reparaturarbeiten eine gute Kenntnis der entsprechenden Anwendung erfordern. Die Gefahr von weiterem Datenverlust ist hoch.
Einige Entscheidungen, die wir gezielt für unsere Infrastruktur getroffen hatten, haben sich aber auch als sehr hilfreich und weitsichtig herausgestellt:
- Alle Anwendungen haben ihre Nutzdaten ausschließlich im PostgreSQL-Cluster sowie entweder in einem CephFS-Volume oder im S3-Object-Storage. Dadurch waren keine Nutzdaten auerhalb von PostgreSQL betroffen.
- Backups werden zwar (noch) im selben Rack, jedoch auf vollständig getrennte Hardware und auf einfachen Storage gemacht. So stellen Komplexitäten wie die von Ceph keine Risiken für das Backup dar.
Weitere Tätigkeiten und Aussicht nach dem Ausfall
Nachdem der Ausfall weitestgehend behoben war, konnten wir den Ausbau des Storages erfolgreich fortführen. Mittlerweile sind alle Festplatten durch SSDs ersetzt und das Ceph gelangt nahe an die Grenze der SATA-Link-Saturation, also die Auslastung des SATA-Buses, an dem die Datenträger selber angeschlossen sind.
Desweiteren haben wir die Gelgenheit genutzt, weitere Optimierungen vorzunehmen:
- Deinstallation von
rsyslogauf allen Debian-VMs, so dass nur noch ein Logging- System (systemd-journald) Logs schreibt - Überprüfung der PostgreSQL-Konfiguration und Anpassung einiger Parameter an neue Messungen und Erfahrungswerte
- Aktivirung eines regelmäßigen
fstrimauf den VMs, so dass Ceph nachhalten kann, welche Blöcke (Objekte) unbenutzt sind und diese bei Maintenance-Operationen nicht berücksichtigen muss
Als nächstes stehen noch einige Tätigkeiten aus:
- Verbesserung der Verteilung von Datenträgern und OSDs auf die Server
Migration von ejabberd zu Prosody und Reaktivierung des XMPP-Servers- Aktives Anschreiben der vom Passwort-Reset betroffenen Benutzer*innen
Update: Mit Hilfe eines von uns entwickelten extauth-Skripts für ejabberd konnten wir ejabberd nun zum OIDC-Login migrieren.

